
A ascensão das plataformas Low-Code revolucionou o desenvolvimento de software. A entrega de aplicações se tornou mais rápida, mas a visibilidade sobre os fluxos internos e a execução das aplicações requer ainda mais atenção. Como garantir a estabilidade, performance e confiabilidade dessas aplicações, especialmente quando elas se integram a arquiteturas complexas baseadas em microsserviços?
Em ambientes distribuídos e de desenvolvimento acelerado, é fundamental compreender como a aplicação se comporta, identificar onde surgem os gargalos e descobrir por que determinados erros só aparecem em produção. Para isso, é importante aplicar uma visão clara do que aconteceu, onde o problema ocorre e por que ele se manifesta. Essa abordagem não apenas contribui para a estabilização do sistema, mas também garante que as equipes de suporte consigam realizar o troubleshooting de forma eficiente, facilitando a manutenção contínua da aplicação e orientando o planejamento das próximas versões.
Você Realmente Sabe o que Acontece com Sua Requisição?
Em uma arquitetura de microsserviços, uma única ação do usuário pode disparar uma cadeia de eventos que atravessa dezenas de serviços diferentes, bancos de dados e APIs externas. Se essa requisição demorar ou falhar, o erro pode estar em qualquer um desses pontos.
Em plataformas como OutSystems, no portal do ODC, você já tem acesso a logs de erros, auditoria de execução, traces para rastrear chamadas de ações e APIs. Isso cobre muito bem os casos comuns de troubleshooting, especialmente durante o desenvolvimento ou validação de qualidade.
Para ambientes corporativos críticos ou que demandam níveis mais altos de observabilidade, o ODC oferece uma base sólida de monitoramento que pode ser potencializada com integrações especializadas. Essas integrações não substituem o ODC, mas ampliam sua capacidade, permitindo atender arquiteturas mais complexas:
- Rastreamento distribuído (Distributed Tracing): Embora o ODC forneça visibilidade interna do comportamento da aplicação, integrações de tracing permitem ir além, oferecendo a visualização completa da jornada de uma requisição entre múltiplos serviços, APIs e microsserviços externos. Assim, em arquiteturas distribuídas, essas ferramentas complementam o ODC ao revelar pontos de lentidão ou falhas fora do seu ambiente direto.
- Análise avançada de logs e métricas: O ODC já disponibiliza logs e métricas essenciais para o monitoramento diário, mas integrações adicionais possibilitam elevar esse nível de análise com recursos como correlação entre eventos, consultas avançadas, dashboards em tempo real e alertas personalizados. Dessa forma, o ODC permanece como a base de operação, enquanto as ferramentas conectadas expandem a profundidade investigativa quando necessário.
Se você está rodando aplicações críticas, com alto volume de transações, integrações externas e SLAs apertados, a observabilidade precisa ser: Centralizada, Correlacionada, Customizável e Proativa. A ODC facilita o uso do Trace/Log Analytics ao adotá-los nativamente e permitir a exportação via OpenTelemetry, mas a responsabilidade de propagação do Trace ID em integrações complexas ainda exige uma configuração deliberada do desenvolvedor Low-Code.
Nesse cenário, Trace + Log Analytics via integração com ferramentas externas complementam perfeitamente o que o ODC oferece, elevando o monitoramento ao nível de observabilidade.
Observabilidade na prática: Distributed Tracing
Quando um fluxo Low-Code chama um serviço externo, e esse serviço chama outro, e assim por diante, o rastreamento da latência torna-se mais difícil usando métodos de monitoração tradicionais ou nativos. O Distributed Tracing (Rastreamento Distribuído) resolve esse problema atribuindo um identificador único, o Trace ID, a cada requisição no momento em que ela entra no sistema.
- Instrumentação: Cada serviço, ou componente Low-Code, deve ser instrumentado para gerar e propagar um Trace ID, garantindo que toda a jornada da requisição possa ser acompanhada de ponta a ponta.
- Spans (Operações): Dentro desse Trace ID são criados os spans, que representam operações específicas, como chamadas de API, consultas ao banco de dados ou a execução de regras de negócio em Low-Code.
- Visualização: As ferramentas de observabilidade coletam esses spans e os exibem em um formato semelhante a um Gráfico de Gantt*, permitindo visualizar a linha do tempo da requisição, identificar a duração de cada operação e detectar onde ocorre maior latência.
*O Distributed Tracing organiza esses spans em sequência e hierarquia, permitindo que o Gráfico de Gantt transforme dados brutos de latência em um mapa visual claro e intuitivo da execução do sistema.
Para instrumentar um ambiente Low-Code. A solução ideal envolve usar gateways de API que injetam automaticamente Trace ID no header da requisição antes que ela atinja o componente Low-Code. Existem ferramentas no mercado capazes de ajudar com essa solução como o Kong, essencialmente de código aberto ou Apigee, para uma plataforma mais robusta, completa e escalável.
Log Analytics: De Arquivo de Texto a Inteligência Operacional
Se o Trace mostra o caminho e o tempo da requisição, os Logs mostram o que aconteceu durante a execução. No entanto, Logs espalhados por diferentes servidores ou armazenados como arquivos de texto podem dificultar diagnósticos em tempo real.
Log Analytics é o processo de coletar, centralizar, normalizar e analisar grandes volumes de dados de log gerados por todos os componentes do seu sistema. Ele transforma informações desestruturadas em dados estruturados e pesquisáveis.
Com Log Analytics, você transforma dados brutos em indicadores visuais de performance, alertas em tempo real, detecção de padrões anômalos e até mesmo diagnóstico de falhas antes do impacto no usuário.
Para que o Log Analytics seja efetivo, seus logs devem ser estruturados, preferencialmente no formato JSON.
- Logs Não Estruturados:
- [2025-11-24 12:00:00] ERRO: Falha ao processar a fatura do cliente 123
- Logs Estruturados:
{
"timestamp": "2025-11-24T15:00:00Z",
"level": "ERROR",
"message": "Falha ao processar a fatura",
"customer_id": "123",
"application": "ERP-LowCode",
"flow_step": "GenerateInvoice"
}
Isso se torna possível no ODC por meio de integrações com diversas plataformas que permitem coletar, correlacionar e visualizar dados de forma avançada, ampliando a capacidade de observabilidade do ambiente low-code sem perder a simplicidade nativa da plataforma.
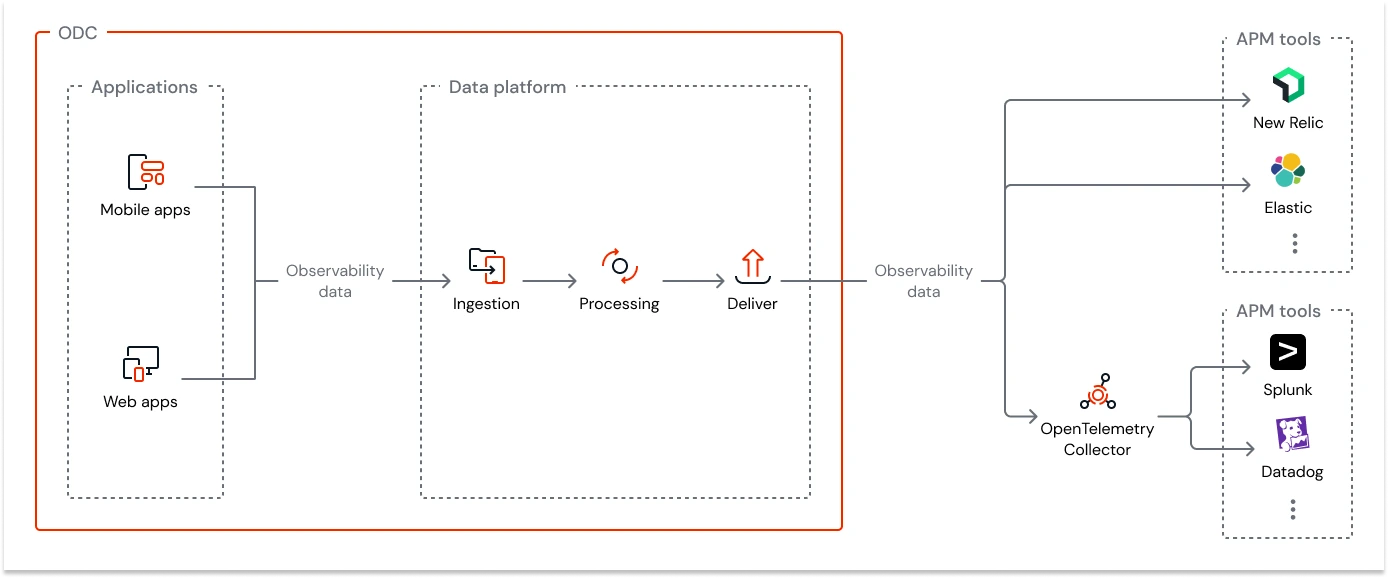
Para saber mais acesse: Streaming observability data - ODC Documentation
O Ponto Chave da Observabilidade
A verdadeira inteligência acontece quando você correlaciona Logs e Traces.
Injeção do ID: O passo mais vital é garantir que o Log ID (ou o próprio Trace ID) seja injetado em cada linha de log gerada por aquele fluxo específico.
Consulta Integrada: Quando o Trace ID mostra que um span demorou 5 segundos, você clica nele e, automaticamente, a plataforma de Log Analytics filtra e exibe todos os logs associados àquele Trace ID e Span ID específicos.
Isso elimina a necessidade de vasculhar manualmente gigabytes de logs para encontrar a causa-raiz, revelando a linha de código ou a regra de negócio Low-Code que falhou.
Etapa | Ação | Ferramentas (Exemplos) | Principal Benefício |
1. Coleta | Centralizar todos os Logs e Spans em um único ponto. | Fluentd/Logstash (para logs), OpenTelemetry Collector (para traces), Agentes de APM. | Unificação da Fonte de Dados. |
2. Padronização | Definir um padrão de Log Estruturado (JSON) com campos obrigatórios: trace_id, timestamp, level, message. | Regras de Negócio na Plataforma Low-Code. | Pesquisa e Correlação Eficientes. |
3. Instrumentação | Configurar APIs e wrappers Low-Code para propagar o trace_id. | SDKs de Distributed Tracing (ex: Jaeger, Tempo) ou soluções nativas de APM. | Mapeamento completo do fluxo da requisição. |
4. Análise | Usar ferramentas que permitem consultas e visualizações avançadas (Kibana, Grafana Loki/Tempo, Datadog, New Relic). | Plataformas de Observabilidade. | Transformar dados em insights acionáveis. |
A adoção de Trace e Log Analytics não é um luxo, é uma necessidade operacional
Plataformas Low-Code oferecem uma vantagem competitiva inegável. No entanto, sua eficácia a longo prazo depende da capacidade da sua equipe de manter a saúde e a performance das aplicações.
Ao integrar esses pilares da Observabilidade em seu ecossistema Low-Code, você move sua operação de um estado reativo (apagar incêndios) para um estado proativo e preditivo. Você garante que a velocidade do desenvolvimento Low-Code não seja comprometida pela falta de visibilidade, construindo não apenas aplicações rápidas, mas sistemas robustos e confiáveis capazes de sustentar o crescimento do seu negócio.
Observabilidade em Ação: O Plano Estratégico na Prática
Transformar a Observabilidade em realidade exige um plano de ação estruturado, especialmente em plataformas Low-Code. Na YasNiTech, nossa experiência demonstra que a chave é a padronização e a centralização dos dados de telemetria.
Estrutura de Log Reutilizável e Integrada
Visando criar uma estrutura de log que não fosse apenas um arquivo de texto, mas uma fonte rica de dados para análise, a Yasnitech focou na criação de um framework genérico dentro da plataforma Low-Code para centralizar a coleta de informações:
- Log Padronizado: Desenvolvemos uma library interna que encapsula toda a lógica de registro, garantindo que todo log siga uma estrutura única (LogEntry).
- Dados Essenciais: Essa estrutura garante a inclusão automática de informações cruciais para o troubleshooting, como UserId (para rastrear o usuário) e, o mais importante, o CorrelationGUID (nosso índice de correlação para Trace).
- Facilidade de Uso: Criamos wrappers (ações simplificadas) específicos para Log de Ações e Log de Erros, permitindo que o desenvolvedor Low-Code registre informações de forma fácil e padronizada, sem se preocupar com a complexidade do JSON subjacente.
- Ação Prática: Ao usar a ação nativa LogMessage, transformamos a estrutura do log em um JSON e o inserimos na mensagem. Isso transforma o log em dado estruturado, pronto para ser ingerido por qualquer ferramenta de Log Analytics.
Sobre a YasNiTech
Fundada em 2013 por ex-profissionais da IBM, a YasNiTech é uma empresa global de tecnologia com unidades em São Paulo, Boston (EUA) e Sansepolcro (Itália). Desde a sua origem, consolidou-se rapidamente no mercado brasileiro entregando soluções inovadoras em combate a fraudes, prevenção de perdas e business analytics.
Com o passar dos anos, a empresa expandiu seu portfólio, incorporando iniciativas em plataformas Low-Code, digitalização e automação de processos. Entre suas inovações, introduziu ao mercado brasileiro a primeira ferramenta de Digitalização de Processos de Negócios Multi-Empresas (Multi-Enterprise Business Process Digitalization), impulsionando a colaboração digital no Supply Chain.
Em sua fase atual, a YasNiTech se posiciona na vanguarda da Inteligência Artificial, com foco especial em Agentic AI. A empresa desenvolve soluções inteligentes e autônomas que potencializam a tomada de decisão, a eficiência operacional e a inovação em múltiplos setores da economia, como saúde, farmacêutico, logístico e industrial.